Desenvolvimento do Oliver
23 de Outubro de 2003
A ordem das exceções foi alterada no protótipo adaptado:| Byte | Palavra 32 bits | Nome |
| 000 | 000 | início |
| 044 | 011 | icache |
| 084 | 021 | mcache |
| 0C4 | 031 | scache |
| 104 | 041 | mensagens remotas |
| 144 | 051 | irq0 - vídeo |
| 184 | 061 | irq1 - serial B |
| 1C4 | 071 | irq2 - teclado ps/2 |
| 204 | 081 | irq3 - mouse ps/2 |
17 de Outubro de 2003
Apesar da operação direta de memória para memória economizar muitas portas lógicas, a temporização é meio problemática. Operando com o relógio de 108 MHz, o dado só fica pronto depois de 4 ns e precisa ser escrito de volta na memória pelo menos 1,4 ns antes do relógio seguinte. Isto deixa apenas 3,8 ns para a operação e seleção de resultado.Uma solução é acrescentar mais um ciclo de relógio à cada operação básica. Isto faria o processador executar efetivamente a 27 MHz. A alternativa adotada foi a inclusão de novos registradores T e S para guardar cópias dos dois elementos do topo da pilha. Os dados aparecem nas saídas dos registradores 1,3 ns depois do relógio e os novos dados precisam estar presentes na entrada 0,8 ns antes do próximo relógio. Isto dá mais de 7 ns para a operação e seleção se feito de uma maneira ingênua. Aproveitando que os dados nas saídas dos registradores estão estáveis desde a instrução anterior, temos 16,4 ns para a operação e seleção.
Os novos registradores ocupam mais portas lógicas, mas o circuito fica até mais simples. Isto pode ser visto na descrição revisada das instruções.
10 de Outubro de 2003
A máquina de estados finitos do cache de instruções foi alterada para lidar corretamente com as várias sequencias de entradas.9 de Outubro de 2003
A atualização do software da Xilinx da versão 5.2 para a 6.1 não resolveu o problema de que a porta serial de 2400 bps estava sendo otimizada a ponto de ter sua entrada totalmente eliminada, o que confundia o software de mapeamento (ele não achava o sinal rx(1) para ligar ao pino indicado). Anteriormente as duas seriais apresentavam problemas em função da lógica simplificada de seleção de periféricos, mas agora a de 38400 bps estava correta. O jeito foi também configurar a segunda serial para 38400 bps por enquanto.8 de Outubro de 2003
Testes dos circuito de vídeo e recalibração da frequencia da portadora da cor. Existe um batimento bem visível para certas combinações de brilho e saturação. Como a frequencia horizontal não é um submúltiplo exato o batimento se move lentamente e fica ainda mais visível. Mas isto é apenas um inconveniente e não um problema sério.Na verdade o teste era mais para ver se continua tudo funcionando com a versão nova (6.1) do WebPack da Xilinx já que algumas pessoas na internet estavam reclamando de não mais conseguir programar componentes via JTAG depois da atualização. Os projetos foram convertidos para o novo formato e tudo continuou como antes.
Quanto ao vídeo, como o padrão especifica um erro máximo na frequência de 20Hz e obtivemos menos de 2Hz isto parecia bem razoável. Mas é provável que sejam estes 2Hz que causam o movimento do padrão de interferância. O circuito de geração de 3.58MHz permite uma precisão tão boa quanto a estabilidade do cristal, de modo que será possível corrigir isto interativamente - aumentando ou diminuindo a frequência em frações de Hz até que o batimento não atrapalhe. Outro fator é que a imagem de teste está sendo gerada sem o entrelaçamento.
7 de Outubro de 2003
A tentativa de integrar os caches de instrução de objetos para facilitar o acesso à memória e a invalidação de blocos do cache de instrução em escritas não deu certo. É melhor mantê-los como blocos separados que se comunicam através de lógica externa. O arbitrador dá preferência para o cache de objetos pois não adianta tentar buscar mais instruções se a atual ainda nem chegou ao fim.Foi criada uma nova página para descrever o progresso do proto-Merlin que é uma pequena adaptação do Oliver para mostrar a possibilidade de um computador doméstico de baixo custo. Esta página está em Inglês para facilitar para alguns dos interessados na máquina.
6 de Outubro de 2003
O cache de pilha foi reorganizado para diminuir o tamanho dos multiplexadores em suas entradas. Todos os fluxos de dados foram listados numa planilha eletrônica, com resultado final assim:inst32.html
Enquanto várias das complicações existentes anteriormente foram eliminadas, ainda não é uma solução ideal. Por exemplo, tanto a saída A como a B podem ser usadas para enviar dados para o cache de objetos (mcache). Isto introduz um multiplexador onde deveriam apenas existir fios.
A solução para este problema é refazer a temporização da instrução write para apenas enviar o endereço no primeiro ciclo e deixar os dados para o segundo ciclo. Isto deixa as coisas mais parecidas com a instrução put e na verdade até dá mais tempo para o cache de objetos reagir ao pedido.
5 de Outubro de 2003
Exceções
Quando ocorre uma situação de exceção no processador, este muda para o quadro zero do cache de pilhas e inicia a execução num endereço diferente para cada exceção:| vPC | nome | descrição |
| 0 | inicializa | a execução começa aqui logo que a máquina é ligada. Na verdade, dada a estrutura do cache de instruções, a execução deveria se iniciar no byte 4 mas é mais fácil fazer todos os registradores terem zero como seu valor inicial. Como a palavra 0 contém zero, quatro instruções dup são executadas desnecessariamente, mas sem nenhum problema. |
| 68 | irq0 | interrupção de vídeo e do leitor de código de barras. Indica ou que o gerador de vídeo chegou ao fim do retraço vertical ou que a entrada de código de barras mudou de valor. No primeiro caso o relógio de tempo real é atualizado e no segundo o contador de endereços de vídeo é usado para determinar a largura da última barra. O contador de vídeo também é usado para se ter uma leitura precisa da hora atual (muito melhor que 60Hz), mas intervalos de espera são sincronizados com o retraço vertical (a cada 16ms). |
| 132 | irq1 | interrupção da porta serial A. Indica que a transmissão do último caracter enviado acabou ou que a recepção de um novo caracter acabou. |
| 196 | irq2 | interrupção da porta serial B. |
| 260 | icache | sempre que um bytecode ou literal não é encontrado no cache de instruções, o bloco é lido da memória. Se não estiverá lá, então esta rotina inicia a recompilação necessária para colocá-lo lá. |
| 324 | ocache | sempre que um campo não é encontrado no cache de objetos, o bloco é lido da memória. Se o objeto não for encontrado na tabela de objetos, então esta rotina descomprime uma cópia da memória Flash. |
| 388 | scache | sempre que uma referência a um quadro que não está no cache de pilhas é feito, esta rotina é chamada para trazê-lo para o cache. |
| 452 | remoto | quando a instrução send tem como destino um objeto em outra tarefa que não a atual, esta rotina cuida dos detalhes da comunicação entre tarefas. |
Os 2048 bytes do cache de instruções podem conter até 1792 bytecodes e a configuração da FPGA é feita de modo que um pequeno programa de inicialização já ocupa esta memória quando o processador começa na instrução 0. Este programa cria as estruturas iniciais na SDRAM ao copiar dados da Flash. Nenhuma das exceções pode ocorrer até que este programa tenha terminado. Em função disso, as portas seriais foram alteradas para só interromperem ao fim da transmissão de um caracter e não quando o buffer está vazio (o que ocorre quando o aparelho é ligado e era usado nos projetos anteriores).
Uma diferença entre as interrupções e as demais exceções é que elas funcionam como subrotinas e continuam a execução do programa original na instrução seguinte à que foi interrompida (que na verdade executou até o fim). As outras exceções precisam tentar executar outra vez a instrução interrompida depois de corrigida a situação que gerou a exceção. No caso da instrução ter sido precedida por extensões do operando, estas também devem ser executadas outra vez (o que exige um ajuste no contador de instruções salvo).
Coletor de Lixo
A mais complicada rotina de apoio ao hardware é o "coletor de lixo" que libera a memória ocupada por objetos que não podem mais ser usados. Usado desde os anos 1960s em linguagens como Lisp, ainda é uma novidade para a maioria dos programadores. Como erros de alocação e liberação de memória são muito comuns isto é importante para evitarmos estes erros.Muitas teses de doutorado foram escritas sobre este tema, mas a interação com processos no Oliver complicam um pouco a coisa em relação à vasta experiência anterior. Quando um novo objeto é criado, ele pode fazer parte da tarefa de quem pediu sua criação ou pode ser o primeiro objeto de uma terefa inteiramente nova. Normalmente uma tarefa tem seus objetos guardados de forma permanente na Flash e estes não são eliminados nunca. Já os novos objetos criados numa tarefa são automaticamente eliminados sempre que sua pilha fica totalmente vazia. Apenas objetos que sejam apontados pelos objetos permanentes da tarefa ou que tenham sido usados como parâmetros de alguma mensagem para outra tarefa são mantidos.
A principal maneira de obtermos mais memória para novos objetos não é a coleta de lixo em si, mas sim a eliminação de tarefas que não estejam sendo usadas e que estejam a salvo na Flash.
2 de Outubro de 2003
O processador funciona com um relógio de 54 Mhz, mas os blocos de memória usados nos caches usam um relógio de 108 MHz. No caso do cache de pilhas isto permite ler dois dados e em seguida escrever dois dados num único ciclo do processador. Já para os caches de instruções e de objetos a velocidade adicional é usada para num primeiro instante comparar o endereço desejado com o armazenado no início do grupo e no segundo instante buscar o dado que foi pedido. No caso de não ser encontrado o endereço, estes dois caches fazem uma segunda busca. Quando esta também falha, então é feito um acesso à memória externa. Assim, o tempo mínimo para um acesso a estes caches é de dois ciclos e o máximo de 3+3x2x(6+2x4)=87 ciclos para o cache de objetos e 2+2x(6+2x8)=66 ciclos para o cache de instruções.O cache de pilhas havia sido projetado para funcionar na borda negativa do relógio de 108 MHz. Isto fazia com que operasse defasado de 90° em relação ao processador. Infelizmente isto não estava dando certo pois a memória da Spartan II mostra o dado que está sendo escrito em sua saída já no início do ciclo de escrita. A solução foi operar a memória na borda de subida, o que na prática torna o atraso de 180°. A parte de leitura fica sendo a segunda metade da instrução e de escrita a primeira metade da instrução seguinte. Como a escrita tem efeito na borda de subida do relógio, podemos considerá-la como ocorrendo no último instante da instrução atual ao invés de metade da instrução seguinte.
1 de Outubro de 2003
Eram necessárias instruções especiais para as rotinas que cuidam de carregar os caches. Por exemplo, as instruções normais de acesso aos registradores locais permitem ler algumas das 256 palavras do cache de pilhas, mas não todas em determinado momento. Mas um truque bem simples pode resolver isto - foi alterada a instrução de alocação de quadros (frames) para usar o registrador 2 (normalmente aponta para o contexto que chamou) do quadro zero ao invés do registrador 3 (normalmente aponta para o contexto léxico que contém o atual). Ai a seguinte sequência pode salvar o quadro 5, por exemplo, na sua posição correspondente na memória principal:
direct push: 5.
frame write: 3 with: TOS. "faz quadro 5 parecer
próximo nível léxico"
frame read: 0x10. "apontador de pilha do quadro 5"
direct push: 0. "indice inicial"
frame read: 0x10. "palavra 0 do quadro 5"
stream next: 5 put: TOS. "registradores 4 e 5"
frame read: 0x11. "palavra 1 do quadro 5"
stream next: 5 put: TOS.
frame read: 0x12.
....
frame read: 0x1E.
stream next: 5 put: TOS.
frame read: 0x1F.
stream next: 5 put: TOS.
A mesma coisa pode ser feita para ler palavras da memória para qualquer um dos 16 quadros do cache de pilha. Note que estas escritas e leituras passam pelo cache de objetos, mas ai temos certeza que este não vai precisar de software para cuidar do caso de um objeto não presente, já que as pilhas sempre estão presentes na memória.Não existe maneira de se escrever informações diretamente no cache de instruções. A única opção é escrever dados nas posições correspondentes da memória externa (segundo nível do cache de instruções) e, em seguinda, invalidar e região afetada. Isto poderia ser feito por uma instrução especial, como é o normal, ou pelo acesso a registradores em endereços especiais. Uma alternativa mais conveniente é fazer o cache de objetos perceber este tipo de escrita e gerar um sinal para avisar o cache de instruções.
30 de Setembro de 2003
Para facilitar o compilador, foram acrescentadas as instruções de ou-exclusivo e de comparação de inteiros. A primeira já existia no Oliver original e a segunda entra no lugar do não (not) que pode ser facilmente implementado com ou-exclusivo com -1.29 de Setembro de 2003
O formato dos números inteiros é o mesmo usado no Squeak:| bits 31 30 29 28 27 25 25 26 24 23 21 20 19 18 17 16 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 | 0 |
| valor | 0 |
O formato de uma referência de um objeto normal é:
| bits 31 30 29 28 27 26 25 24 23 22 21 20 | 19 18 17 16 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 | 0 |
| tarefa | objeto | 1 |
A tarefa de número 0 é especial, pois cada um de seus objetos também é uma tarefa (mesmo os oito primeiros objetos, que incluem nil, true e false, podem ser considerados assim). O conteúdo de uma tarefa consiste de sua tabela de objetos locais seguida pela pilha de execução. Cada elemento da tabela de objetos representa as duas primeiras palavras daquele objeto. A primeira contém o endereço físico do resto do objeto e a segunda aponta para o "mapa" do objeto, que define seu tipo e contém seus métodos. As primeiras 16 palavras de uma tarefa, no entanto, contém uma cópia do atual contexto de execução (a não ser quando a tarefa está sendo executada) de forma que os oito primeiro elementos da tabela de objetos não são válidos. Este não é o caso da tarefa 0, cujo contexto atual sempre está dentro do processador.
28 de Setembro de 2003
O pessoal da linguagem Beta (da Dinamarca) implementou no Self um "editor estruturado" que se parece bastante com a sintaxe adotada no Neo Smalltalk. A comparação com os recursos semelhantes no Squeak mostra que não é fácil adaptar uma infraestrutura criada pensando em outras aplicações para este tipo de editor.27 de Setembro de 2003
Os periféricos são todos de 16 bits, o que era bem adequado para o projeto original do Oliver. Agora o processador é de 32 bits, mas as memórias externas continuam de 16 bits de modo que seria necessário um circuito de adaptação de qualquer forma. Uma opção interessante seria mudar os periféricos para 8 bits de modo a reduzir pela metade o número de linhas do barramento. Infelizmente a economia não se mostrou muito grande e é conveniente transferir os dados e "status" de uma única vez, tanto na escrita como na leitura. A alternativa seria ter uma linha de endereço para escolher entre os registradores de dados e os de configuração/status.A memória do circuito de vídeo foi reduzida pela metade (de 16 palavras de 16 bits para 16 bytes) e foi eliminada a interface de programação do "registrador de fase", que agora tem seu valor carregado pelos últimos quatro bytes da tela. Ainda assim, são dois registradores de 32 bits para gerar o 3.58MHz e mais um de 20 bits para gerar o endereço.
Os seguintes periféricos devem gerar interrupções ao invés de exigir que o processador fique lendo seu registrador de status: som/vídeo/barras, serial 1, serial 2 e usb. O primeiro circuito interrompe no fim de cada tela ou quando muda o valor da entrada do leitor de código de barras. O software lê o endereço atual do circuito de vídeo para determinar quanto tempo se passou desde a última interrupção com uma precisão melhor de que um micro-segundo. Isto permite manter por software um relógio de tempo real e saber a largura das barras que estão passando pelo leitor.
26 de Setembro de 2003
O compilador que foi criado para o dietST está sendo adaptado para o processador de 32 bits. A idéia original era gerar "bytecodes" quase identicos aos executados pelo processador para que carregá-los no cache de instruções de nível dois fosse apenas uma questão de copiar blocos de memória. E isto está sendo implementado no momento, mas uma alternativa para o futuro seria guardar as "árvores de sintaxe" criadas pelo editor e gerar os bytecodes cada vez que forem necessários. Isto é semelhante à solução adotada para o Oliver de 16 bits, mas um pouco mais dinâmica.25 de Setembro de 2003
As operações das tabelas de instruções que podem causar uma leitura de memória externa de dados foram marcadas em azul. No caso mais simples, em que o objeto em questão pode ser encontrado numa tabela na SDRAM, o hardware pode se virar para ler (ou gravar) os dados. Se o objeto se encontra comprimido na Flash então um programa especial precisa ser chamado para expandí-lo. Teoricamente, isto poderia encher a memória e um ou mais objetos da SDRAM teriam que voltar a ser guardados apenas na Flash. Na prática, dados os tamanhos relativos dos dois tipos de memória no Oliver isto nunca acontece.Já na tabela com todos os 256 bytecodes, as cores foram usadas para indicar instruções que não fazem sentido. Infelizmente o hardware que evitasse tais instruções seria maior e mais complexos do que uma versão que as inclue, de modo que fica por conta do software (compilador) nunca gerar estas sequências de bits.
24 de Setembro de 2003
As duas primeiras tabelas da página mencionada dia 23/9 foram alteradas para incluir uma descrição mais precisa da operação de cada instrução. A notação usada não é exatamente o VHDL mas a complexidade é bem próxima. As operações indicadas por vermelho ou verde podem precisar da ajuda de software para executarem.23 de Setembro de 2003
Foi criada uma nova tabela em http://www.merlintec.com/swiki/software/3.html para mostrar todas as 256 combinações de bits possíveis para as instruções. Na verdade é mais fácil entender apenas 26 instruções, considerando "jmp 3" e "jmp 4" como a mesma instrução com operandos diferentes. Mas a tabela torna mais fácil visualizar o hardware e o compilador.Os arquivo do projeto 15k no software da Xilinx foram copiados para um novo projeto chamado 50k. As versões de software da uart e video foram eliminados, bem como o dietST.
22 de Setembro de 2003
A programação da CPLD foi alterada para carregar a FPGA usando uma região diferente da Flash quando a máquina é ligada com duas teclas pressionadas. As teclas curto circuitam duas linhas da CPLD, o que faz com que o endereço A17 da Flash seja zero e não um como é normal. As teclas usadas nos teste foram "P" e "X", mas serve qualquer uma da terceira linha do teclado junto com a que está logo abaixo. Como esta segunda região da Flash está apagada, fica possível programar a FPGA pela interface JTAG. Isto facilita bastante o desenvolvimento e mais tarde será usado para carregar configurações novas do hardware via a porta serial. Em tese seria possível gravar diretamente por cima da região normal, mas isto seria bem arriscado.Curiosamente, a programação anterior da CPLD não deveria ter funcionado dado que esta alteração deu certo. Ele inicia o contador de 18 bits de endereço com tudo zero, inclusive o A17. Mas acontece que neste circuito anterior a contagem atinge todas as combinações possíveis de endereço, inclusive as que tem A17 em um. Assim, o circuito estava errado pois enviava 128KB de 0xFF para a FPGA antes da programação correta, mas funcionava pois a FPGA simplesmente ignorava estes bytes extras. A programação estava levando o triplo do tempo necessário, mas nem dava para notar isto. Quando o resto da Flash não mais tivesse em branco, provavelmente teríamos uns erros bem estranhos.
O circuito atual da CPLD tem um pequeno problema, pois enquanto a FPGA está limpando sua memória (INIT='0') os dois pinos que estão sendo curto circuitados pelas teclas estão com valores opostos. Funciona assim mesmo, mas não é boa idéia e é trivial de se corrigir.
21 de Setembro de 2003
No conjunto de instruções do processador, "state write: .. in: .." ficou bem diferente das demais por usar 3 elementos da pilha. Isto exige pelo menos dois ciclos de relógio pois o hardware do cache da pilha tem apenas duas portas de leitura. Mas o grande problema é que várias instruções anteriores são necessárias para colocar estes 3 elementos na pilha que dai somem de uma só vez. Se quisermos gravar uma posição vizinha, temos que começar o processo outra vez.No projeto original do Oliver tinhamos registradores dedicados para esta função, de modo que apenas um elemento era retirado da pilha. Ai o problema era outro - se estamos lidando com mais de um objeto então estes registradores tem que ser constantemente recarregados, o que é tão ruim quanto a solução atual. Para diminuir o problema, o Oliver tinha dois conjuntos de registradores dedicados, cada um com suas instruções separadas.
Uma alternativa melhor seria ter instruções parecidas com as do Oliver mas que pudessem ser explícitas quanto aos "registradores" que devem ser usados. Dado o cache de pilha, seria melhor usar variáveis temporárias como estes registradores. Algo do tipo:
a soma: b com: c
| t ao ai bo bi co ci |
t := b tamanho.
ao := a.
ai := 0.
bo := b.
bi := 0.
co := c.
ci := 0.
[bi < t] enquantoVerdade: [
stream next: 9 put: (stream next: 11) +
(stream next: 13)
]
Este método ocupa exatamente as 16 posições de um bloco da pilha, mas não é muito típico. O "9" acima se refere ao "registrador" que contém a variável temporária "ai". Depois de executada a instrução, o valor de ai é incrementado. Se o registrador indicado tivesse sido par ("ao", neste caso) então o indíce não seria incrementado. O grupo de registradores envolvidos na instrução é sempre um par indicando o objeto e o seguinte indicando o índice.O acesso a campos calculados de objetos (#at: e #at:put:) pode ser facilmente implementado com estas novas instruções:
obj at: ind
^ stream next: 4
obj at: ind put: d
stream next: 4 put: d.
^ obj
Com estas operações implementadas como métodos ao invés de instruções primitivas, a solução de 9 de Setembro para acesso a outros níveis léxicos deixa de ser prática. O jeito é adotar algo mais tradicional, como a convenção de que quando o número do registrador é maior que 16 os bits mais significativos (gerados com uma instrução de extensão) indicam o nível léxico.19 de Setembro de 2003
A solução para o problema do teclado foi dividir o programa em dois processos paralelos - um que envia os caracteres para varrer o teclado 10 vezes por segundo e outro que apenas recebe os resultados e os transforma em eventos para o programa principal. Este segundo foi alterado para terminar quando uma mensagem #fim chegar na entrada e não mais quando uma variável pronto se tornar falso. Isto evita os erros que sempre occoriam no encerramento do programa.O software de leitura de código de barras está interferindo com o teclado. Na verdade seria melhor se o hardware indicasse o início do grupo de caracteres representando o estado do teclado (com um caracter zero, por exemplo) para que o software não perdesse sincronismo. Os dados do leitor se parecem com o esperado (para barras no formato "2 de 5 intercalado" usado pelos bancos brasileiros) mas não está perfeito pois o número de barras brancas e pretas não está batendo totalmente. Além disso, as barras largas estão apenas com o dobro da largura das finas e deveriam ter o triplo (uma inspeção visual das barras de teste mostram que elas estão corretas - o próprio leitor está diminuindo a diferença).
18 de Setembro de 2003
A parte do teclado do programa em Squeak funciona durante um certo tempo e depois fica esperando alguma coisa. Foi configurada para amostrar umas dez vezes por segundo e o multiplexador conta com isso para evitar atrasos no recebimento de caracteres pela porta serial.17 de Setembro de 2003
Parece que o fornecimento dos componentes da Philips de interface USB será um problema para a fabricação do Oliver. Ainda estamos aguardando reposta da Arrow e a Avnet só lista uma versão anterior do chip mas sem disponibilidade. Um projeto Japonês disponível na Internet dispensa este chip e usa apenas 3 resistores e 3 pinos da FPGA. Um destes resistores é usado para a indicação de velocidade numa interface tipo periférico e nem seria usado numa interface tipo "host" como a do Oliver.Na primeira versão da placa XSV da Xess eles tentaram algo assim para terem duas portas USB com apenas quatro pinos da FPGA. Só que não deve ter funcionado pois na versão da Philips eles incluiram o PDIUSBP11A, mesmo ao custo de terem apenas uma porta USB no lugar das duas. Vendo a especificação USB e o projeto Japonês, deu para perceber que o primeiro projeto deles estava errado pois não tinha como desligar o resistor de "pull up" quando necessário. Este problema aparece apenas nas interfaces tipo periférico.
Seria possível alterar o layout to Oliver para que pudesse ser soldado o chip da Philips ou então os dois resistores ligando diretamente o conector à FPGA. Assim, na fabricação haveria uma escolha de qual solução adotar dependendo da aplicação e da disponibilidade de componenetes.
16 de Setembro de 2003
O software em Squeak estava levando muito tempo para escrever na tela de cristal líquido. Boa parte do problema é que um atraso de 6 milisegundos estava ocorrendo de propósito após cada caracter enviado. Como os dados e o controle para o LCD estavam sendo enviados por canais diferentes, a falta deste atraso muitas vezes alterava a ordem e o mesmo caracter era enviado repetidas vezes ao invés de serem caracteres diferentes. Uma solução alternativa foi combinar os dois canais do LCD num único nesta parte do programa. Isto permitiu eliminar o atraso extra. Devido ao número de caracteres que precisam ser enviados pela serial para escrever um único caracter na tela e à velocidade limitada da serial, ainda leva um tempo perceptível para re-escrever toda a tela. Mas está muito melhor do que antes.Diferentemente do indicado no manual da Winstar, este LCD opera como se tivesse duas linhas de 40 caracteres cada, e não 64. A primeira linha visível começa no endereço 0, a segunda em 40, a terceira em 20 e a última em 60. Quando caracteres estão sendo escritos na segunda linha e "vazam" para a quarta, tudo funciona como esperado. Mas se o endereço é alterado diretamente para a posição 60, apenas os tres primeiros caracteres aparecem na quarta linha. O quarto aparece no fim da terceira linha e o quinto em diante no início da segunda. Uma rotina para escrever a tela toda de uma única vez contorna bem este problema, mas uma solução real seria mais interessante.
15 de Setembro de 2003
Um problema da configuração atual do protótipo é que fica difícil examinar os sinais da placa com o osciloscópio em função do painel frontal. Felizmente o cristal líquido está usando apenas 16 dos 20 sinais do conector e foi possível ligar fios nos demais (um terra e tres sinais, mas usamos apenas dois em função do osciloscópio só ter dois canais).O plano de testes do processador se baseia na idéia de criar pequenos "loops" e usar os sinais obtidos como descrito acima para verificar algum detalhe do funcionamento. Como os pinos fazem parte do nível mais alto do projeto, para ligar sinais internos dos sub-blocos será necessária uma convenção de que cada um destes sub-blocos deve ter uma "porta de testes" de dois pinos distinta dos sinais normais. A cada teste, a porta de testes de apenas um sub-bloco é ligado aos pinos e os demais ficam em aberto. Para outros testes o arquivo VHDL é alterado para ligar um sub-bloco diferente à saída. No caso de sub-sub-blocos o mesmo processo se repete.
14 de Setembro de 2003
Depois de estudados os "application notes" da Xilinx XAPP201 a 204, deu para perceber que a implementação de memórias associativas (CAM - content access memory) nas FPGA é muito ineficiente para ajudar na parte de cache de dados.No Oliver de 16 bits o cache de dados e instruções era combinado e haviam duas portas na memória usada - uma de 16 bits e outra de 64. Isto permitia a comparação de 3 grupos de 21 bits cada um num único ciclo de relógio. Como o número do objeto e o deslocamento eram de 15 bits cada um, em princípio faltavam 9 bits por grupo. Mas dois bits selecionavam uma palavra dentro de um bloco e 6 bits selecionavam o bloco. O bit restante vinha de uma pequena memória auxiliar.
Com apenas dois blocos de memória para o cache de dados, a mesma porta de 32 bits será usada tanto para ler os dados como para fazer a comparação de endereço. Teoricamente, seria necessário 32 bits para indicar o objeto e mais 32 bits para o deslocamento. Na prática, os objetos serão indicados por apenas 24 bits e o deslocamento por 8 (com uma extensão para 32 bits como descrita abaixo).
Os 64 blocos de 4 palavras cada são divididos em quatro grupos de 16. Dois bits do deslocamento selecionam a palavra dentro do grupo e uma função do número do objeto e do deslocamento gera os 4 bits que selecionam um bloco dentro do grupo. O grupo zero contém os endereços e os 3 outros grupos os dados. As 3 primeiras palavras de cada bloco do grupo zero contém os respectivos endereços dos blocos correspondentes em cada um dos 3 outros grupos. A mesma função que gera os 4 bits mencionados acima também gera um quinto bit, que é usado para selecionar se será a palavra 0 ou a 1 a ser comparada com número de objeto e deslocamento. Se o resultado da comparação for negativo, então a palavra 2 é comparada em seguida. Assim, o terceiro bloco de dados serve de "reserva" tanto para o primeiro como o segundo e podemos dizer que o cache tem uma associatividade de 1,5.
Sempre que os oito bits de deslocamento numa palavra de endereço for 255, o verdadeiro valor se encontra na palavra 3 do bloco de endereços. Isto cria a restrição de que apenas um dos tres ocupantes de um bloco lógico do cache pode representar um deslocamento maior que 1024 palavras. Como objetos maiores que umas poucas palavras são extremamente raros, isto não deve ser um problema.
13 de Setembro de 2003
Como o cache de instruções tem 512 palavras, se metade delas forem de bytecodes teríamos por volta de 1000 instruções. Isto indica que a complexidade de um programa que rodasse totalmente no cache é equivalente a o que cabe numa PIC 16F84, por exemplo. Em função disto, um teste inicial interessante para o processador é fazê-lo simular o hardware de terminal que usamos para "falar" com a aplicação em Squeak. Uma extensão seria uma rotina para gravar da Flash com uma velocidade bem superior ao circuito de teste da Flash. Neste caso o novo teste já seria o programa que seria usado na produção do Oliver.12 de Setembro de 2003
Logo que a FPGA é programada, o processador depende de uma série de estruturas na memória principal para operar mas infelizmente esta ainda está em branco. O conteudo inicial das memórias internas e flip-flops da FPGA são determinados pelo arquivo de programação, de modo que é possível inicializar o cache de instruções com um pequeno programa de "bootstrap".O mais fácil é ter todas as tabelas necessárias na Flash (de forma comprimida) para que a rotina de bootstrap seja uma simples operação de cópia (com descompressão trivial).
Programas de teste que caibam inteiramente no cache de instruções podem pular a sequência de bootstrap completamente.
11 de Setembro de 2003
Um ponto bem crítico do projeto é o cache de instruções. Ao contrário do Oliver de 16 bits, não é viável criar uma tabela com todas as combinações possíveis de tipos e mensagens pois ocuparia bem mais que os um ou dois megabytes daquela versão.Uma solução mais dinâmica envolve os PICs (polymorphic inline caches) que associa pares tipo/endereço destino a cada instrução de envio de mensagem. Isto permite toda uma série de otimizações pelas quais o Self se tornou conhecido. Nesta primeira fase apenas umas poucas otimizações mais simples serão usadas, mas o potencial para técnicas avançadas está presente.
A memória cache é dividida em 64 blocos de 8 palavras cada uma. A palavra 0 de cada bloco contém o endereço representado por aquele bloco, de modo que apenas 7 palavras são aproveitadas para conteúdo. Uma região da memória principal é reservada como cache de instruções de nível dois e blocos são automáticamente lidos desta memória para um dos blocos internos sempre que necessário. Em certas situações o bloco procurado não existe no cache de nível dois e neste caso entra em ação um software especial para criá-lo das estruturas de dados (objetos, métodos, etc) na memória principal.
Dado o apontador de instruções, uma função de "hash" gera um número de 6 bits indicando o bloco com a instrução. A palavra zero é lida e comparada e se não for a desejada os 6 bits são invertidos e o processo repetido. Se nenhum dos dois blocos for o desejado então ele é carregado da memória (substituindo um dos dois blocos).
Os operandos das instruções substituem os bits inferiores do apontador de instruções, de modo que os literais são encontrados nos mesmos blocos que os bytecodes.
PICs
A primeira vez que uma instrução de envio de mensagem é executada, o literal associado é buscado do cache de instruções. O fato de ser um seletor interrompe a execução da instrução provocando a execução de uma rotina especial. Esta rotina procura o destino da mensagem e se este já estiver no cache de nível dois a instrução de envio é alterada para usar o endereço deste destino como literal.Quando uma instrução de envio já modificada é executada, o literal associado indica um endereço de destino. A palavra deste endereço é buscada e comparada com o tipo do objeto no topo da pilha. Se forem iguais, a execução continua com a palavra seguinte. Se forem diferentes, o próximo literal (indicado por seis bits no primeiro literal obtido) é buscado e o processo continua até que uma rotina com o tipo certo seja encontrada ou a lista ligada chegue a um seletor ao invés de número (este caso é tratado pela rotina especial mencionada logo acima).
10 de Setembro de 2003
O cache de pilha tem 16 blocos de 16 palavras cada um. Os dados de cada bloco são semelhantes aos definidos para o dietST, mas não exatamente os mesmos:| 0 | apontador de topo de pilha |
| 1 | apontador de instruções |
| 2 | bloco de quem enviou a mensagem |
| 3 | bloco do próximo nível léxico |
| 4 | primeiro parâmetro |
| 5 | segundo parâmetro |
| . | ... |
| n | parâmetro n-3 |
| n+1 | primeira variável temporária |
| n+2 | segunda variável temporária |
| . | ... |
| n+m | variável temporária m |
| n+m+1 | início da pilha de dados deste bloco |
| . | ... |
| x | fim da pilha de dados deste bloco, onde x são os quatro bits inferiores da palavra 0 |
| . | ... |
| 15 | fim do bloco |
Todos os blocos de um processo são alocados em múltiplos de 16 palavras, de modo que seus quatro bits inferiores sempre indicam diretamente uma das palavras do bloco. Em princípio, os quatro bits de baixo das palavras 2 e 3 seriam sempre zero em função disso. Na verdade, estes bits são usados para indicar qual dos 16 blocos do cache contém a cópia do bloco desejado. Se forem zero, então este bloco não está no cache e precisa ser lido.
O bloco zero do cache é especial, sendo permanentemente reservado para tratamento de interrupções. Blocos livres no cache de pilhas são mantidos numa lista ligada e a instrução "context new" pega o primeiro elemento desta lista. Se este era também o último elemento, então uma interrupção é gerada invocando uma rotina que salva um ou mais blocos para a memória e os coloca na lista de blocos livres.
9 de Setembro de 2003
Os vários aspectos da linguagem Smalltalk foram examinados para verificar que o conjunto de instruções definido é suficiente. A falta de instruções de "nível léxico" presentes no Self e Slate (e alguns outros Smalltalks) não é problema pois a sequêncialexLevel 2 readLocal 4pode ser simulada como
frame read: 3. "contexto externo ao atual" state read: 3 in: _. "mais um nível para fora" state read: 4 in: _. "finalmente a variável desejada"Aqui temos 3 bytes ao invés de 2, mas como o nível léxico mais frequente é o 1 isto não vai aumentar significativamente nem a memória ocupada nem o tempo de execução.
O maior problem com este esquema é que 'state read:in:' pode ser chamado para objetos que na realidade só existem no cache de pilha. O hardware para detetar esta situação talvez seja mais complicado do que umas duas ou tres instruções a mais.
8 de Setembro de 2003
Vários testes revelaram que não é possível programar a FPGA via cabo JTAG se a CPLD conseguir programá-la da Flash ao ser ligado o aparelho. Isto não tinha acontecido na primeira placa e tinha acontecido inicialmente na segunda, tendo depois desaparecido sozinho. Procurando na Internet foram encontrados vários problemas parecidos, mas não exatamente este. Na produção isto não será um problema e mesmo no desenvolvimento é mais um inconveniente (a CPLD pode ser apagada e o cabo JTAG volta a funcionar depois de desligado e religado o aparelho. Dai a CPLD pode ser programada outra vez), do que um problema sério.Os circuitos de teste de vídeo e de memória foram alterados para funcionarem com o relógio de 27Mhz. Assim, a placa mais nova foi agora totalmente testada. O circuito de vídeo foi alterado para gerar uma variedade maior de cores (do que poderiam ser representadas em 8 bits por pixel) mas isto não deu certo - as cores ficaram fracas e com um enorme "batimento". É provável que a frequência de 3,58MHz esteja bem fora, de modo que isto foi deixado de lado para ser calibrado por software no futuro.
6 de Setembro de 2003
O novo conjunto de instruções do processador de 32 bits foi criado com uma forma mais "tradicional", usando instruções de 8 bits cada uma. A maior modificação real em relação às instruções tipo MISC definidas anteriormente para o Oliver é o uso do cache de pilha, como no processador de 4/16 bits.26 instruções foram definidas por enquanto - 12 que recebem um parâmetro de quatro bits (que pode ser extendido via duas destas instruções) e 14 que operam apenas com a pilha. As que estão faltando do conjunto de 5 bits são: 'auxAtInc:' e 'auxAtInc:Put:' (já que não existe mais o objeto auxiliar), 'swap:' e 'over:' (seriam raramente usadas e o compilador pode se virar com 'frame read:' e 'frame write:with:', bem como 'not' e 'xor:' (que podem voltar a ser incluidas se testes mostrarem que sua falta prejudica o desempenho, mas em princípio podem ser simuladas por sequências de outras instruções). O envio de mensagens e colocação de objetos literais na pilha são agora instruções de 8 bits também, e não os dois bits inferiores de cada palavra. Não existe mais o registrador SF e nem a instrução de envio de mensagem para este registrador, pois como na linguagem Slate todos os parâmetros podem participar da seleção do código e não apenas o primeiro.
As novidades são: 'extend positive:' e 'extend negative:' (para aumentar o parâmetro da instrução seguinte em 4 bits), 'end returnFar:' (antes só havia o equivalente ao 'end returnNear:' e o compilador tinha que gerar toda uma sequência de código para restaurar a pilha para o contexto mais externo antes de voltar), bem como 'context new' e 'context grabArg' (para criar um novo contexto de execução explicitamente, já que o envio de mensagem não faz isso, e para transferir dados entre o contexto antigo e o novo).
5 de Setembro de 2003
A figura abaixo mostra o tamanho relativo das várias FPGAs que podem ser soldadas na placa do Oliver (os blocos grandes representam 192 CLBs, lógica, cada um enquanto que os pequenos representam 4Kbits de RAM).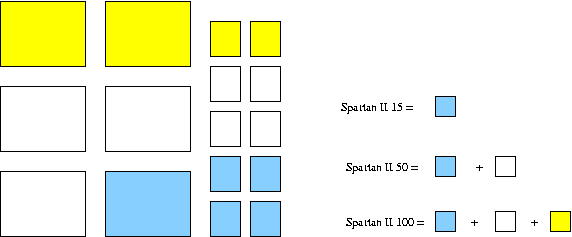
Curiosamente, a Spartan II 100 tem apenas 50% mais lógica e apenas 25% mais memória que a 50. A melhor solução é dedicar metade da 50 ao processador e metade aos periféricos. Cada metade destas é o dobro dos primeiros Olivers, mas como o processador é de 32 bits ao invés de 16 o "aperto" é o mesmo (em relação a um processador ocupando a Spartan II 15 inteirinha como em alguns testes que foram feitos, pois em relação a um processador e periféricos numa 15 a situação é muito melhor!). Com relação à memória, serão os mesmos tres tipos de cache do projeto dietST - de pilha, de dados e de instrução. Cada processador (dois, no caso da Spartan II 100) terá seu próprio cache de pilha feito de dois blocos de memória (256 palavras de 32 bits - 16 blocos de 16 palavras cada) mas os outros dois serão partilhados por todos os processadores.
4 de Setembro de 2003
O software do teclado foi alterado para não ter uma pausa entre cada caracter enviado pela serial. Um erro inicialmente fez com que cada leitura indicasse o estado anterior do teclado, mas isto foi corrigido (faltava um caracter na sequência de 16 que devem ser enviados).Para o projeto do processador de 32 bits serão combinados as idéias anteriores do Oliver de 16 bits e coisas que foram aprendidas no projeto de 4/16 bits. As instruções de 5 bits tipo MISC (processador Forth) serão substituidas por "bytecodes" mais tradicionais.
3 de Setembro de 2003
Aproveitando o Squeak, vários pequenos programas testaram diferentes aspectos de textos no cristal líquido e opções de cursor.A Rosângela e José trouxeram dois novos protótipos do Oliver, já com a FPGA de 50 mil portas e com a montagem mecânica correta, como mostra a foto.

Foram testadas separadamente as duas cpus novas e duas fontes. Também foi testado um novo cabo JTAG. No início estava bem complicado programar a FPGA e depois de testadas todas as alternativas ficou claro que o problema era no conector de 10 pinos do cabo JTAG. Corrigido isto foram testados todos os aspectos que já estavam funcionando nas placas anteriores, mas o teclado novo não estava dando certo. A melhor alternativa foi simplesmente eliminar os capacitores de filtro. Além disso, a pinagem do teclado estava errada (havia sido alterada para funcionar com o circuito original do teste de teclado). Uma tecla estava com defeito em um dos teclados, mas isto foi corrigido.
2 de Setembro de 2003
O programa em Squeak no PC agora dispara vários processos para cuidarem do fluxo de caracteres pelos diversos canais da serial.1 de Setembro de 2003
Um circuito alternativo para gerar os pulsos no teclado cabe na CPLD, mas exige uma forma de onda mais complexa vinda da FPGA. Com esta alteração o circuito não cabia mais em 15 mil portas. Uma solução bem diferente é deixar o software no PC varrer o teclado no lugar de um circuito dedicado. O canal 1 do PC para o terminal foi dedicado para a geração dos pulsos do teclado e a cada dois caracteres enviados por este canal um outro volta pelo canal 2 com o resultado da amostragem das 8 primeiras linhas do teclado.31 de Agosto de 2003
Com o circuito do teclado alterado para poder tanto funcionar com o atual teclado de 20 teclas quanto com o novo de 40 teclas, o software da Xilinx não conseguia mais fazer caber na FPGA. Observando os relatórios e a planta do chip programado dava para ver que ainda haviam bastante recursos livres apesar de todos os bloco estarem ocupados (cada bloco tem quatro subcircuitos, de modo que um bloco pode estar apenas parcialmente ocupado). O WebPack sugeria tentar outra vez o programa "map" mas com a opção "-r" (não ordenar os registradores) para contornar o problema. Realmente, experimentando isto na linha de comando deu certo. A questão era como fazer isto de dentro da interface gráfica para coordenar com os demais subprogramas. Acontece que esta opção normalmente não é mostrada para o processo "map", mas se as preferências do projeto forem alteradas para "advanced" dai é possível configurar isto graficamente.O circuito foi gravado na Flash e a programação da CPLD foi alterada para gerar os sinais adicionais para o teclado de 40 teclas. Infelizmente o resultado foi grande demais para a CPLD de 36 macroblocos. Isto não deve ser complicado de resolver, mas só para um teste rápido foram eliminados 5 dos 7 pinos do teclado. Desligando e ligando o aparelho a nova programação da FPGA entrou direto, mas não deu para ver no osciloscópio os pulsos esperados nos dois pinos restantes do teclado.
30 de Agosto de 2003
Foram feitos um grande número de testes diferentes com o circuito multiplexador, e tudo parecia estar como esperado. Finalmente foi feito um teste complexo, em que o número do canal foi substituído por uma seqüência de oito digitos. Assim, deveria aparecer "\01234567A" mas o resultado foi "\AAAAAAAAA" indicando que o multiplexador havia funcionado desde o início e que a memória fifo é que estava com defeito.Examinado o circuito que havia sido implementado e comparando com informações no manual da Spartan II ficou claro que na verdade haviam tres erros diferentes. Por uma grande coincidência, eles se cancelavam para o caso em que um caracter é lido toda vez que um é escrito, de modo que a memória se alterna entre vazia e exatamente um caracter. Todos os usos da fifo testados são exatamente este caso e a primeria excessão foi quando o multiplexador tentou envia 3 caracteres seguidos. O primeiro ("\") funcionava pois a outra serial lia imediatamente. O terceiro (o caracter que o dispositivo realmente queria enviar) também funcionava pois ficava guardado no registrador de saída da memória. O problema era o segundo (número do canal) que acabava ficando igual ao terceiro no lugar do que deveria ser.
Não foi implementado o circuito de duplicação da "\" no multiplexador pois esta situação é extremamente rara e pode ser compensada no software. Também foi verificado que existe "bounce" nas chaves usadas no teclado - ao ser solta ela indica vários contatos espúrios. Não compensa tentar resolver isto por hardware. O software pode simplesmente ignorar quando uma tecla parece ser pressionada seguidas vezes em menos de um décimo de segundo.
29 de Agosto de 2003
O circuito do teclado foi implementado, mas um erro na pinagem causou muitos problemas. Isto foi corrigido e agora está funcionando. Cada vez que uma tecla é pressionada ou solta, o seu valor e status são enviados. Desta forma, o PC pode saber se uma tecla continua pressionada ou não. Não foi incluído a capacidade de lidar corretamente com múltiplas teclas pressionadas ao mesmo tempo ("n key rollover").O contador do circuito do leitor de código de barras foi aumentado de 15 para 21 bits (sendo que continuam sendo enviados os 7 bits mais significativos para cada leitura). Isto permite uma boa faixa de velocidades de passagem do documento pelo leitor (os números nem ficam grandes demais com uma leitura lenta nem pequenos demais com uma leitura bem rápida).
28 de Agosto de 2003
Foi implementado o multiplexador para misturar dados de várias origens na porta serial que ligado com o PC. A convenção é a mesma do demultiplexador (só que a duplicação de "\" não foi implementada). O canal 0 representa a serial do Bloqueador, o canal 1 os dados do leitor de código de barras e o canal 3 é o teclado.O circuito do leitor de código de barras transmite uma contagem de 7 bits e o valor atual do leitor. Isto permite ao software descobrir as larguras das barras.
De um modo geral o multiplexador funcionou, mas o caracter depois da "\" está errado.
27 de Agosto de 2003
O demultiplexador foi implementado de modo que "\" seguido de um número de "0" a "3" escolhe o respectivo "canal" para os próximos caracteres enviados pela serial. O próprio caracter "\" pode ser enviado se repetido duas vezes ("\\" é interpretado como um símples "\"). O canal 0 é a segunda serial (do Bloqueador) e funcionou sem problemas.O canal 2 é o dado a ser enviado para o cristal líquido, enquanto o canal 3 envia os sinais de controle para o mesmo cristal líquido (e controla o backlight). Assim, a sequência "\2A\3030" mostra um "A" na tela.
Este circuito ocupa totalmente a FPGA, de modo que foi introduzido um novo parâmetro nas portas serial para que seus contadores não sejam maiores que o necessário (9 bits em uma e 14 bits na outra - anteriormente as duas usavam contadores de 15 bits). Isto liberou uma área razoável que deve ser suficiente para os demais periféricos (desde que o som seja simplificado para gerar apenas ondas quadradas).
Como este projeto está funcionando bem, foi gravado na Flash e a CPLD foi configurada para carregar a FPGA ao ser ligada. Não deu certo, e o circuito da CPLD foi alterado para levar em conta as mudanças na placa (o arquivo já havia sido gravado na Flash de byte em byte e não repetido como na primeira placa). Continuou a não funcionar e foram feitos vários testes que demonstram que a FPGA nunca libera o pino "DONE". Isto pode indicar que não está recebendo os bytes certos da Flash.
O problema foi finalmente resolvido invertendo o bit menos significativo do endereço gerado pela CPLD, de modo que os bytes ímpares são enviados para a FPGA antes dos pares.
26 de Agosto de 2003
Um simples circuito para inverter o sinal cada vez que acionado foi incluido em diferentes pontos da máquina de estados finitos de recepção da serial para descobrir em que ponto estava travando. Só que com este circuito de monitoramento a serial nunca trava. Foram experimentados todos os pontos em que o estado é de recepção e o único em que o circuito não impedia o travamento foi o ponto em que é detectado o meio do último bit.O esquema a nível de RTL ("register transfer logic") forma examinados e o circuito gerado pela linha inserida é exatamente o que era esperado. Sem este circuito ou no ponto em que ainda trava, o esquema da porta serial parace bem menor, o que pode indicar alguma otimização exagerada numa das ferramentas da Xilinx.
25 de Agosto de 2003
Varios testes confirmaram que o circuito estava travando quando recebendo um caracter do PC. Todos os contadores estava parados, o que não faz sentido nesta situação. Para obter estes resultados, a porta serial foi modificada para indica sua situação em dois sinais que podiam ser ligados a pinos observados pelo osciloscópio.24 de Agosto de 2003
Um adaptador permitiu ligar o Oliver ao Bloqueador, mas a tentativa de comunicação do Hyperterminal via FPGA com o Bloqueador não deu certo. Foram feitos testes cada vez mais básicos sem resultado. Ligado o PC diretamente ao Bloqueador ficou confirmado que este estava funcionando, e também ficou claro a falha - o Oliver e o Bloqueador tem a mesma pinagem pois ambos foram feitos para serem ligados a um PC. Dois (dos 3) pinos do conector com o Bloqueador foram trocados e todos os testes passaram a funcionar, inclusive o circuito do dia anterior.De vez em quando o circuito trava (quando o Bloqueador envia vários caracteres seguidos), sendo necessário reprogramar a FPGA (na verdade apenas reinicializá-la). Foi feita uma alteração em que uma memória de 512 bytes foi colocada entre as duas seriais em cada uma das direções, mas ai parou de funcionar. Corrigidos uns erros e com um pequeno atraso no sinal que indica inicio de transmissão o funcionamento ficou igual ao do circuito original em termos de estabilidade.
23 de Agosto de 2003
Foi criado um circuito para permitir o acesso a todos os periféricos do Oliver via uma das portas seriais. Isto permitirá testes remotos via um programa rodando num PC.Uma porta serial foi configurada para 2400 bps e outra a 38400 e foram ligadas entre si. No osciloscópio parecia que a conversão de velocidade estava funcionando, mas não deu para ligar o Bloqueador no Oliver pois os dois usam conectores DB9 fêmea.
22 de Agosto de 2003
A idéia inicial era criar um editor gráfico no Squeak Smalltalk para lidar com programas escritos em Neo Smalltalk, mas isto iria ficar um pouco complicado. Desta forma foi adotado que a sintaxe inicial seria a tradicional e o compilador SmaCC foi usado como ponto de partida. Apenas foi necessária a criação de uma nova classe para gerar código para o dietST. Isto funcionou quase que totalmente (falta lidar com blocos) com otimização para as mensagens #ifTrue:ifFalse:, #ifTrue:, #ifFalse: e #whileTrue:.Foram acrescentadas duas instruções para acesso a outros blocos da pilha de dados além do atual. Originalmente a idéia era aproveitar as mesmas instruções pushTemp e popTemp: com o número de bloco zero (reservado para o bloco das interrupções) indicando o atual, mas existe espaço para diversas instruções adicionais e são necessárias menos portas do que com poucas instruções mais complicadas.
O circuito estava ficando muito complicado com duas portas de 4 bits em cada pilha. A tentativa de se trasferir 8 bits de dados por ciclo de relógio era um caso de otimização prematura. Todos os caminhos entre os blocos foram reduzidos para 4 bits e a segunda porta dos caches de instruções e da tabela de objetos foram eliminadas.
21 de Agosto de 2003
Cada umas das 3 pilhas definidas anteriormente foi implementada num bloco separado com lógica adicional. A pilha de dados inclui todo o circuito de execução das instruções, enquanto que a pilha da tabela de objetos é responsável por gerar endereços para o controlador de memória.19 de Agosto de 2003
Ao invés de ser criado um novo projeto para o dietST, o projeto original foi modificado para que ficasse mais fácil escolher o processador e os periféricos de maneira independente. O processador e cache anteriores foram agrupados num único block chamado "oliver15". Bastar trocar o chamado deste bloco por "dietST" para compilar a nova arquitetura.18 de Agosto de 2003
O processador RISC do curso de projetos de processadores, que deveria caber numa FPGA XC4005 de 5 mil portas, não coube na Spartan II 15.Foi criada uma arquitetura nova especificamente para ocupar o menor espaço possível na FPGA ao custo de uma redução na velocidade. O software de alto nível continua exatamente igual apesar das diferenças nos detalhes da implementação (descrita em Inglês em dietST).
O principal fator de redução do tamanho é a operação em 4 bits da cada vez com dados de 16 bits. As informações são guardadas em memória ao invés de registradores, o que também reduz o tamanho mas exige mais ciclos de relógio.
A memória de blocos da FPGA foi dividida em 3 caches especiais:
- cache de pilha (16x16): guarda cópias dos contextos de execução. Dados como apontador de pilha, contador de instruções, parâmetros, variáveis temporárias, a pilha local e outros ficam aqui e não em registradores
- cache de tabela de objetos (64x4): permite achar o endereço físico e tipo de cada objeto
- cache de instruções (128x4): as instruções são de 4 bits, mas de uma maneira geral são equivalentes ao conjunto de instruções do Oliver
16 de Agosto de 2003
Foi implementado o processador Forth de 16 bits do Dr. Ting (http://www.ultratechnology.com/p16vhdl.htm) para ajudar a ver como reduzir o tamanho deste tipo de projeto. Anteriormente o circuito havia sido compilado para Spartan II 50, mas o uso de memória distribuída para as pilhas no lugar de registradores discretos o fez caber no Spartan II 15, mesmo aumentando o tamanho das pilhas de 8 para 16 palavras. Infelizmente o chip ficou inteiramente ocupado pelo processador, não sobrando espaço para os periféricos. Movendo as pilhas para as memórias em bloco reduziu um pouco a ocupação, mas não significativamente.Também foi experimentado o processador RISC GR0040 do Jan Gray (http://www.fpgacpu.org/gr/index.html). Este coube com uma folga um pouco maior além de já incluir periféricos como porta paralela e temporizador.
15 de Agosto de 2003
Apesar de ser recomendado o uso de multiplexadores em FPGA no lugar de barramentos de alta impedância, alguns dos projetos otimizados para circuitos da Xilinx usam esta segunda técnica. Substituindo os multiplexadores dos dados de periféricos e memórias por um barramento a ocupação caiu para 11% e ainda restam muitos "tbufs" (circuitos de alta impedância) para serem usados em outras partes do projeto.14 de Agosto de 2003
Uma simplificação radical é fazer a serial por software, como no bloqueador. O circuito ficaria limitado a um registrador de saída e 38400 interrupções por segundo seriam suficientes para uma ligação de 9600. A modificação foi feita de tal modo que basta escrever "suart" no lugar de "uart" no arquivo principal. A ocupação da FPGA cai de 87% para 48% quando as duas seriais são eliminadas desta forma. O vídeo tem um contador de 24 bits e ao ser eliminado (deixando o som) a ocupação cai para 17%.A Rosângela entregou uma especificação do Oliver e ficou marcado para 25 de Agosto uma demonstração desta aplicação para seu cliente.
12 de Agosto de 2003
O circuito de video e som foi implementado. A memória cache passou a usar os block RAMs da FPGA. Inicialmente isto foi feito deixando o próprio compilador VHDL descobrir que isto era possível, mas depois foi introduzida uma chamada explícita aos blocos primitivos da Xilinx.8 de Agosto de 2003
Os testes de serial continuaram. A impressão é que o compilador VHDL está embaralhando as coisas, o que seria péssimo se for verdade. O mais provavel é que tenha um erro muito sutil na lógica do circuito.7 de Agosto de 2003
O circuito de teste da Flash foi modificado para operar em 27MHz e funcionou perfeitamente. Em seguinda, a porta serial foi alterada para operar com um relógio pré-dividido, o que permite substituir os vários contadores de 11 bits por contadores de apenas 2 bits. Quando só a transmssão tinha sido alterada ela funcionou, mas quando a recepção também foi alterada (e funcionou) a transmissão passou a sempre enviar coisas erradas.6 de Agosto de 2003
Foram implementadas as versões definitivas do circuito do teclado, do LCD (e código de barras) e seriais. O resultado ocupa quase todo a FPGA sem o processador e controlador de memória.4 de Agosto de 2003
Cada sub-bloco foi re-escrito para que a ferramenta não possa eliminar totalmente seus circuitos.30 de Julho de 2003
Varias alternativas de multiplexação dos dados dos periféricos e memória foram implementadas e comparadas, sendo escolhida uma com um mux 4:1 seguido por outro de 2:1. A maior parte do tempo nas semanas seguintes foi gasto com o software e não está detalhado nesta página.25 de Julho de 2003
Os arquivos definitivos do circuito Oliver de 15 mil portas estão sendo criados, com os subcomponentes sendo definidos separadamente. Um circuito chamado mult2, por exemplo, gera o sinal de inicialização e duplica o relógio externo. Diversos pequenos detalhes tiveram que ser corrigidos para que isto fosse testado e o resultado foi uma saída muito "limpa" de 54MHz.22 de Julho de 2003
Ficou pronto o segundo protótipo do Oliver. Substituindo a placa original pela nova na giga de teste, o software de programação via JTAG reconheceu a CPLD e FPGA e conseguiu carregar com sucesso o circuito de teste de cristal líquido. Nada aparecia na tela, mas o backlight podia ser ligado e desligado pela tecla E5. Uma divisão por dois do relógio de 27MHz fez com que o texto aparecesse no LCD, mas a parte do teclado estava instável. Dividindo o relógio desta parte por 2 também melhorou muito, mas a fileira 1 de teclas estava faltando (o que era esperado pela alteração de layout). Uma alteração no arquivo com a pinagem pareceu não ter efeito.Foi testado o circuito do oscilador, onde deu para ver o efeito da alteração do pino 140 para 141 da FPGA no conector do teclado. A mudança no arquivo .UCF corrigiu isto. Voltando para o circuito do LCD deu para ver que esta alteração não tinha sido salva lá e quando isto foi feito o teclado passou a funcionar 100%.
4 de Julho de 2003
Foi alterada a página Oliver para indicar em azul os aspectos que foram eliminados da versão de 15 mil portas. Também foi alterada a definição da instrução "pushLiteral" com operando de 5 bits para que possa ser usada justamente com os objetos mais populares.Ao longo da semana foram estudados diversos esquemas para adaptar funcionalidades adicionais do Merlin à versão completa do Oliver. Várias das soluções, com tabelas auxíliares e diversos tipos de compactação, são muito interessantes. Mas a conclusão final é que a alternativa mais prática é simplesmente tornar o Oliver50 uma implementação do Merlin. Ou seja, teria um único processador de 32 bits no lugar de dois de 16 bits. Como cálculos que envolvem números de mais de 32 mil ficariam mais rápidos e muitas das direções consideradas se tornariam desnecessárias, a perda de desempenho seria relativamente pequena. A vantagem da compatibilidade total de software com o Merlin é a eliminação de limites pequenos (como máximo de 8 mil nomes de mensagens ou de 30 mil objetos) e a continuação do desenvolvimento mesmo depois de "pronto" o projeto Oliver.
30 de Junho de 2003
Como apenas os dois primeiros protótipos do Oliver usarão uma FPGA de 15 mil portas lógicas, não compensa gastar muito tempo tentando fazer o projeto inteiro caber neste espaço. Foram consideradas alternativas, como o processador para ColorForth originalmente planejado para o Oliver, mas a melhor solução é começar com uma versão reduzida do projeto atual. Vamos chamar isto de Oliver15 e a versão completa de Oliver50. As simplificações sendo consideradas são as seguintes:- sem cache de blocos: elimina registradores FA0-FA7, FB0-FB7, FO, FP, FA, FB e a lógica de CFA e CFB (são os mesmos registradores que FA e FB mas seu acesso causa efeitos diferentes). O compilador ainda pode implementar blocos inteiramente por software, mas fica bem mais lento.
- sem múltiplas tarefas: elimina registradores SO e RO.
- pilhas fixas de 16 posições: os registradores SP e RP são reduzidos de 16 para 4 bits e toda a lógica de interface com a memória é eliminada. Programas muito recursivos deixam de funcionar.
- sem objeto auxíliar: os registradores AX e AO são eliminados, bem como as instruções "auxAtInc:Put:" e "auxAtInc:". Mover blocos de dados de um objeto para outro continua possível, mas fica bem mais lento.
- sem objeto global: o registrador GO não é necessário e só foi incluido no projeto para deixar o número de registradores 32 redondo (o que não é o caso com as simplificações) e para que o software tenha um espaço rápido para guardar informações.
- vídeo preto e branco: só o contador de 32 bits de ajuste da frequência de cor ocupa 1/6 da Spartan II 15.
27 de Junho de 2003
As instruções do Oliver foram alteradas para ficarem iguais à versão atual do Merlin. Isto facilita o desenvolvimento do compilador para as duas máquinas.A página Teste do Oliver mostra o que aconteceu antes desta data.
Links to this Page
- Oliver last edited on 2 October 2006 at 9:16:32 pm by 192.168.1.23
- Teste do Oliver last edited on 13 October 2003 at 8:18:58 pm by gandalf.merlintec.com