Synchronous Message Passing
The Self language used in the Merlin project is a new implementation, rather than a port of the one created by the Self group at Stanford and Sun for Sparc machines and written in C++. The idea is that it should track the "official" Self closely enough so as to be able to run the tests and benchmarks and to be able to use as many of the original ".self" and ".sm" files as possible.
The differences in the implementations are explained below and, in some cases, represent ideas developed to make Smalltalk ( used in the project up to 1990 ) a practical commercial product. Other differences are due to the use of Self as the operating system for the "bare" hardware, which is somewhat more modest than that required by Self 4.0.
It is intended, however, that Merlin Self always track the Stanford/Sun definition as closely as possible, and not develop along a diverging path. The last thing the world needs is yet another programming language.
The justification and details are given elsewhere, but the extended reflection capabilities defined were meant to allow the implementation to be written in Self as much as possible. An object's "meta-space" can be accessed by send the object the '_meta' message.
It would seem that mirrors are no longer needed in Merlin as an object can directly present a reflective interface to clients. There are some cases where it is not possible to handle objects directly, however. Mirrors are also used for backwards compatibility with Self 4.0.
A simple model where there is one task per object was chosen to avoid the usually confusing semaphores and other parallel programming gear. Message sends are synchronized by "future objects" that serve as place holders while the receiver computes the reply. The sender can continue as long as it doesn't try to send a message to this "future". Some things are harder in this model, but it is easier to understand.
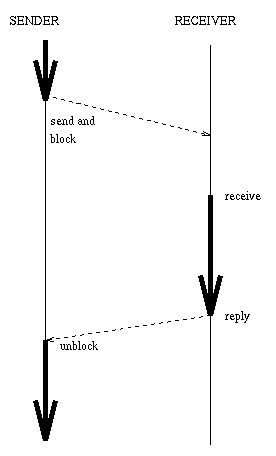
The main idea of this "wait by necessity" model is that it should be as compatible as possible with sequential code while allowing a good amount of parallelism. The following figures show alternative message passing models:
| |
This model is totally compatible with sequential code. It can't be used to introduce parallelism, however. |
| The advantage of this model is simplicity - it has one less primitive than the previous one. It is very easy to make mistakes in pairing "sends" and "receives", unfortunately, and the code is usually different from what programmers are used to. | 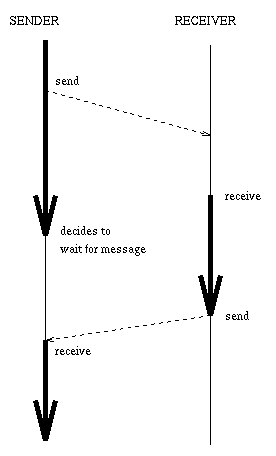 |
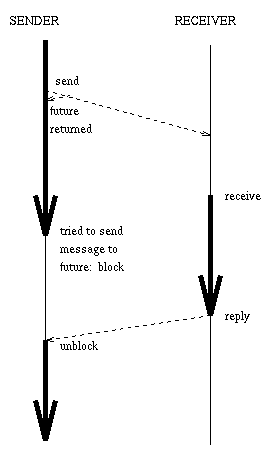 |
This model combines the parallelism of the asynchronous model with the compatibility of the synchronous model. |
Though the wait by necessity figure shows the same method that sent the original message blocking on the future object, that doesn't have to be the case. The object might be passed around as an argument in messages to other objects, and they might be the ones that will block. The final reply has the effect of unblocking all objects that have tried to send a message to the future and of making the future "become" the answer so that objects can now send messages to the former future without blocking. So the reply is to the future object, and not to the original sender as the figure seems to imply (it was drawn that way to show the analogy with the synchronous message passing model). In fact, Merlin Self does not store the sender of a message anywhere.
One popular optimization that is absent in Self 4.0 is tail recursion elimination. The reason for this is that a difference can be seen in the behavior of a program relative to the theoretical model when the debugger is used. It was considered worth including in Merlin (Merlin actually uses a generalization: tail call elimination with reply forwarding) as it enhances the parallelism that the wait by necessity model can extract from an application.
Though the "wait by necessity" model mostly hides the parallelism from the programmer (except for the boost in performance on systems with multiple processors) things become very different when an error occurs. In a single threaded model, an error (a division by zero, for example) brings the whole application to a halt. If we calculate "x factorial + (1/y)" in parallel and y turns out to be zero, the CPU will continue to work on "x factorial", possibly for a long time yet.
An error model similar to that used in functional languages was developed for Merlin. When a message is sent, a future object is instantly returned (as explained above) to stand for the eventual answer. If an error occurs during the calculation of that answer, then the future turns into a "poisoned context". Sending a message to a "poison" will cause the sending context to become poisoned itself. Any method blocked waiting for a future that becomes poisoned also becomes poisoned itself. So this spreads the effect of the error slowly through the whole application. The only way to handle a poison safely is by using a mirror on it. This is encapsulated in the following control structure:
x factorial + (try: [1/y] Else: 0)
The "try: block Else: expression" will return the expression if the block becomes poisoned. If the expression is a block, it can take as an argument a mirror on the poison to determine the nature of the error. By the way, I know that the expression in the above example should be infinity rather than 0, but this made the example look neater.
Mirrors on poisons form a hierarchy of errors, so it is easy to query it to find out what happened in as much detail as desired:
anyError
systemError
messageError
argumentCountError
lookupError
messageNotUnderstoodError
ambiguousMessageError
missingDelegateeError
mathError
divisionByZeroError
overflowError
badSignError
memoryError
badAlignmentError
badIndexError
badSizeError
writeProtectionError
outOfMemoryError
stackOverflowError
stackUnderflowError
ioError
linuxError
EPERM
ENOENT
...
parserError
prematureEndOfInputError
primitiveFailedError
badTypeError
userDefinedError
This list is still under construction will will, no doubt, change in the next few releases. The organization of errors into a hierarchy makes testing the name of the error unnecessary, but it can still be done for compatibility (in the Fail: blocks in primitives, for example). All poisons can report their type, their name and a mirror on the "failed" context. Error handling code might change things and attempt to re-execute the failed code, or might simply abort it. It might transform the error into a message - in the case of the messageNotUnderstoodError, for example. A poison might also have other information available to help the handling code.
The problem with the system described so far is that it does nothing to prevent the needless execution of code that will be affected by an error in some expression being evaluated in parallel. Future versions of Merlin will have accounting software in the scheduler, so that objects can't accept messages that have no "credit", Each user session has a major account from which credit is obtained. A normal message send makes the receiver share the same account as the sender, but a separate sub-account may be optionally created. Each major user action starts a new "transaction" that gets its own sub-account. An error causes the corresponding account to be "frozen", which stops all parallel processing related to that task in a single stroke. The error handling code might chose to thaw the account to let (at least) parts of the task to continue.
A single image is shared on a network by many users. A simple protection scheme is intended mainly to avoid nasty accidents that that are prone to happen in this environment. The basic idea is that every object is marked as belonging to another object, which normally represents some user in the system. Objects are grouped together in "partitions" on disk, and to read or write objects in a given partition the user must have a pointer to an object in it and present a "ticket" generated by that partition's creator giving the appropriate permissions.
An important use of the protection system is avoiding the corruption of prototypes. All objects are created as clones of some prototype, and may then be edited as needed. Forgetting to first clone the prototype will result in the edits modifying the prototype itself, leading to undesirable results the next time it is used. A lot of Self code guards against this possibility ( "copy removeAll", for example ), but the solution in Merlin is to make the prototypes belong to a special user. The empty list prototype, for example, might belong to some "collection user". If a normal user forgets to clone the prototype, an error will occur when the user tries to edit it. The system is still fully open as you can log in as the collection user and edit the prototype if that is what you really want to do.
An interesting side effect of the protection system is that any object can be considered immutable if no one with write permission is currently logged in the system. If that is the case, then the object may be replicated in as many nodes as needed and it can execute any number of messages at the same time. This greatly enhances the system's performance. If someone with write permission tries to log in, however, then all replicas of his objects must be eliminated first. This may slow down logging in by many seconds, but is a better solution than fine grained object coherency schemes.
The ability to interactively create objects and use them in programs makes software development a lot easier. File systems are no longer needed, which makes the machine more friendly to novices. The persistence system is linked to the protection system in that it is divided into regions, each one of which only contains objects belonging to a single user. A user may have any number of regions, on the same disk or scattered across the network, forming a distributed shared memory system.
Some hardware configurations where this implementation is to run do not have much memory, so the implementation will include a simple threaded code compiler, which is little more than a sophisticated interpreter. Also, since the compiler is written in Self, the system must be able to run without it while "bootstrapping".
Unlike Self, which invokes primitive methods inside the monolithic virtual machine, the idea for Merlin is to have primitive objects instead. So we would write
_arithmeticUnit add: 12 With: 21
instead of
12 _IntegerAdd: 21
Here are some of the primitive objects that will be needed:
It should be easy to add new primitive objects with time (a MMX object would be popular now), eventually even dynamically.
This implementation runs on the bare hardware and must include many of the feature that X Window normally takes care of. This is, no doubt, the most serious difference as it will make graphical applications non-portable. Future versions should fare better, however, as it is intended that the Merlin graphics model should be a close superset of the morphic model.