A Tiny Implementation of Self
"If you think yourself clever, set yourself to do
something, and you will have a chance of humiliation."
- George MacDonald
current implementation: Release 1
This simple implementation of an interpreter for the
Self language has certainly proved this quote to be
true. If you have found yourself excited by what you
have read in the other pages about Merlin, I am afraid
that "when the rubber meets the road" things are a little
less spectacular.
Release 0
Please note that this is not really a Self interpreter at all
but just a parser for the Self language written in C. See
the status and next release
sections on this page for information about a real interpreter.
Linux users can simply grab the
executable for the text-only
version of tinySelf (the parser). In addition, the
Self files must also be present
if you want to test non trivial programs with this.
These Self sources were written by the Self group
at Sun Microsystems Laboratories. So tinySelf is only possible because
of the efforts of: Bay-Wei Chang, Craig Chambers, David Ungar, Elgin Lee,
John Maloney, Lars Bak, Mario Wolczko, Ole Agesen,
Ole Lehrmann Madsen, Randall B. Smith, and Urs Hoelzle. Neither they,
nor Sun, nor Stanford are responsible for any problems you may have
with these files.
Sources
You can download the full C sources of
tinySelf.
To be able to compile and link tinySelf, you will need the conservative
garbage collector by Hans-J. Boehm and Alan J. Demers at
SGI or
Xerox Parc. Note
that a copy of the file gc.h is included with the tinySelf source files.
This was not necessary - I did this while I was learning how to use
CVS and thought that every file needed an ID line for it to work. It
doesn't hurt, though, and the original copyright is there.
Features
If you do download this, then you can run it just by typing "ts1" at
the Linux prompt. Nothing will seem to happen since the prompt is
missing (a previous version had it) so just type a Self expression.
The parser then lists the bytecodes that represent that expression,
followed by a line with a number indicating the error level (0 means
no errors) and then the file name and line number. This will always
be the file STDIN since the _RunScript command has been removed.
So if you type
3+4
the system will say
push 4
push 3
send +
-----0------------------
<stdin>:1,0
Bugs
- handles obsolete things like inner methods and privacy declarations
- simply quits on certain errors (missing colon in Cap Keywords and
a few bad syntax errors). This is not worth fixing since this will be
replaced with Self code later on. Don't make syntax errors :-)
Status
After this code was released in November, 1995, two efforts were
made to develop it into a full Self interpreter. Since they were
not completed, the source for them has never been released (but
if anyone is interested I can send them a copy). C is great for
implementing well designed projects, but not as good for trying
out different ideas. So real progress only came about by halting
this effort and starting all over in Self (Release 1). No futher
development will be done on the C tinySelf. Linux users will
have to wait for Release 3 - sorry.
Release 1
This is a quick and dirty implementation of tinySelf only
intended to test the compatibility of the parallelism model
with existing Self applications. The idea is also to generate
enough statistics to do a good job on the "real" implementation.
Sources
The current working version of the source files are always
available for download as ts1.self.gz.
You must uncompress it with gunzip and can then read
it into Self 4.0 with
bootstrap read: 'ts1' From: 'merlin'
if you place it in a 'merlin' subdirectory. This is advisable
as the transporter will try to save it there by default if
you make any changes.
Features
The reason it is called "tinySelf" is that it is too slow
to run anything but "toy programs". It does include
most of the features planned for Merlin Self ( see what
the differences relative to
Self 4.0 are )
You execute tinySelf by giving it a string containing a Self
expression to evaluate, like
tinySelf eval: '(2@3)+(4@5)+(6@7)'
This places the result, the Self object 12@15, in your "hand".
A side effect of every expression evaluation is that the stats
object is first cleared and then accumulates statistics that
can be viewed as bar charts.
tinySelf stats showConcurrency
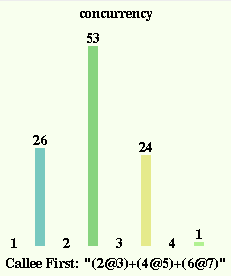 This returns an outliner for a morph, which when viewed looks like
this picture. The top of the chart indicates the type of statistic,
concurrency in this case. At the bottom of the chart we see what
scheduler was used (more on this later) and the expression that
was evaluated. The concurrency chart shows, for a given number
of concurrent objects (those ready to execute at some instant),
how many interpreter steps were executed with that condition. So
26 interpreter steps (roughly bytecodes plus message sends) found
only one object ready to execute. During 53 step there were exactly
two objects ready. For 24 steps there was a concurrency of three
while a single step saw a peak of four objects ready to execute
at the same time. This is normally a Gaussian curve, and its
peak can be used as a rough estimate of the average parallelism
that tinySelf extracted from this piece of code.
This returns an outliner for a morph, which when viewed looks like
this picture. The top of the chart indicates the type of statistic,
concurrency in this case. At the bottom of the chart we see what
scheduler was used (more on this later) and the expression that
was evaluated. The concurrency chart shows, for a given number
of concurrent objects (those ready to execute at some instant),
how many interpreter steps were executed with that condition. So
26 interpreter steps (roughly bytecodes plus message sends) found
only one object ready to execute. During 53 step there were exactly
two objects ready. For 24 steps there was a concurrency of three
while a single step saw a peak of four objects ready to execute
at the same time. This is normally a Gaussian curve, and its
peak can be used as a rough estimate of the average parallelism
that tinySelf extracted from this piece of code.
When an object sends a message to another object it receives a
"future object" as a temporary answer and can continue to run.
If the receiving object was idle, the ammount of concurrency
in the system is increased by one. In practice, however, the
interpreter only executes bytecodes from one object at a time,
the running object. The rest are placed in a ready queue. With
the Callee First scheduler, which generated this graph, the
object that received the message will execute on the next step
while the sending object is moved from running to the ready
queue. This should produce behavior closest to a sequential
implementation of Self (in theory, because in practice
things are much more complicated).
We can choose another scheduler before evalutating an expression:
tinySelf scheduler: tinySelf callerFirstScheduler.
tinySelf eval: '(2@3)+(4@5)+(6@7)'.
tinySelf stats showConcurrency
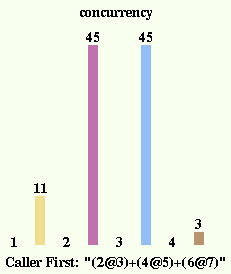 This scheduler places the called object in the ready queue and
lets the calling object continue to execute on the next step.
For this particular code, this scheduler resulted in more
parallelism than the previous one. But much more important
than that, the Self expression gave the exact same result
even though there was a great difference in the order that
the bytecodes were executed (the total number of steps didn't
change, of course). The very purpose of this tinySelf implementation
is to find out for how much existing Self code (and considering
it typical of programs yet to be written) this is true. Self
specifies evaluation order of arguments in expressions very
carefully, but any program that depends on this won't work
with tinySelf.
This scheduler places the called object in the ready queue and
lets the calling object continue to execute on the next step.
For this particular code, this scheduler resulted in more
parallelism than the previous one. But much more important
than that, the Self expression gave the exact same result
even though there was a great difference in the order that
the bytecodes were executed (the total number of steps didn't
change, of course). The very purpose of this tinySelf implementation
is to find out for how much existing Self code (and considering
it typical of programs yet to be written) this is true. Self
specifies evaluation order of arguments in expressions very
carefully, but any program that depends on this won't work
with tinySelf.
The third scheduler is called the Interleaved Scheduler. After
every interpreter step it places the running object at the end
of the ready queue and fetches the first one from that queue
to execute next. This round robin execution of all ready objects
results in an execution order close to that which would happen
on a shared memory parallel machine with an infinte number of
processors.
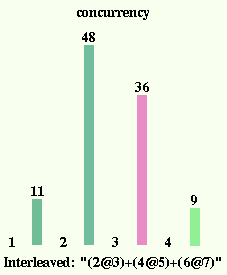 It was surprising to me that this scheduler found more parallelism
than the others. I thought that switching between all the object
would increase the chance of encountering a situation where the
object has to block, but it seems that if that happens there
is an even greater increase in the opporunities to start up
new computations. If this is confirmed in larger application, it
will be a very interesting result indicating the possibility
of using massively parallel machines, as the parallelism will
increase as we add CPUs instead of diminishing until we get
saturation.
It was surprising to me that this scheduler found more parallelism
than the others. I thought that switching between all the object
would increase the chance of encountering a situation where the
object has to block, but it seems that if that happens there
is an even greater increase in the opporunities to start up
new computations. If this is confirmed in larger application, it
will be a very interesting result indicating the possibility
of using massively parallel machines, as the parallelism will
increase as we add CPUs instead of diminishing until we get
saturation.
There are several other kinds of graphs that can be generated
by the stats object. Not all of them are very interesting for
simple expressions like the one in this example. Sending the
message 'showWaits' to stats generates this picture.
 A naive implementation of the parallelism model would cause
a deadlock for any recursive code (where an object sends
a message to itself indirectly, since selfSends are handled
separately). Whenever an object blocks on another message
there is a check for this kind of deadlock and, if one is
detected, a message is brought to the front of the object's
message queue to let execution continue. The graph's title
indicates the number of times this happened during the
execution of the given expression (never, in this case).
The algorithm must step
through a (potentially) arbitrary graph looking for cycle,
which can be very inefficient. The bars of the picture
show roughly what the actual branching structure of graph
was like. In this case, all five nodes examined had no
branches at all. As long as nearly all nodes have no or
only one branch then the algorithm can be optimized for
the case of simple lists.
A naive implementation of the parallelism model would cause
a deadlock for any recursive code (where an object sends
a message to itself indirectly, since selfSends are handled
separately). Whenever an object blocks on another message
there is a check for this kind of deadlock and, if one is
detected, a message is brought to the front of the object's
message queue to let execution continue. The graph's title
indicates the number of times this happened during the
execution of the given expression (never, in this case).
The algorithm must step
through a (potentially) arbitrary graph looking for cycle,
which can be very inefficient. The bars of the picture
show roughly what the actual branching structure of graph
was like. In this case, all five nodes examined had no
branches at all. As long as nearly all nodes have no or
only one branch then the algorithm can be optimized for
the case of simple lists.
You can also try tinySelf stats showBytecodes to see
the dynamic distribution of the virtual machine's intructions.
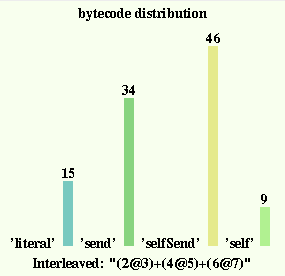 Only four of the eight different bytecodes show up in this
graph. This is very typical as the index entension bytecode
would only be used with very large methods having more
than 32 literal objects, while the other three bytecodes
are used for resends (which are not at all common in most
Self code). The distribution of the bytecodes shown here
is probably representative of most programs, except that
the number of 'self' bytecodes is likely to be normally
lower than this.
Only four of the eight different bytecodes show up in this
graph. This is very typical as the index entension bytecode
would only be used with very large methods having more
than 32 literal objects, while the other three bytecodes
are used for resends (which are not at all common in most
Self code). The distribution of the bytecodes shown here
is probably representative of most programs, except that
the number of 'self' bytecodes is likely to be normally
lower than this.
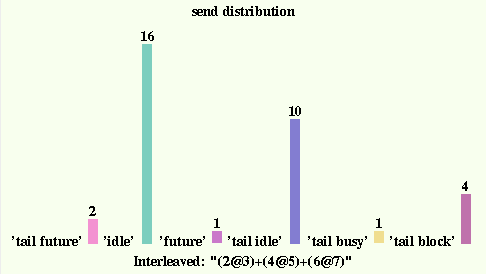
A much more interesting graph is obtained by the expression
tinySelf stats showSends. This shows how the 34 send
bytecodes from the previous figure were treated by the tinySelf
interpreter. This implementation makes a distinction between
sends that are either the last bytecode in a method or
followed by a return bytecode. These are marked as 'tail' in
the graph. This is important in tinySelf because the result
of the send can be forwarded directly to the sender of the
currently executing method, which frees the object to start
on a new method and avoids creating another future object.
The downside (and the reason Self 4.0 doesn't have tail
message elimination) is that information is destroyed that
would be needed when debugging.
When a message is sent, it might involve a block, a future,
a busy object or an idle one (which combined with tail
elimination makes for a total of eight possibilities).
Messages to blocks (or with blocks as arguments) or to future
objects suspend the sender until the result is ready. Messages
to busy objects (those already executing some message) allow
the sender to continue, but the message is queue so the ammount
of parallelism doesn't increase. Messages to idle objects
allow both the sender and the receiver to execute in parallel.
The figure shows that this is the most common case, which is
why tinySelf is "embarassingly parallel".
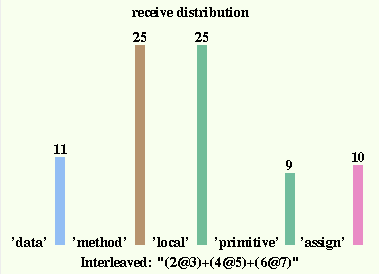
Another way to view messages is to look at what the receiver
does with them. There were 80 messages in this example (34
sends plus 46 selfSends) and tinySelf stats showReceives
shows how they were distributed. The 25 messages marked as
'local' were selfSends that matched slots in the block
or method that sent them - this includes constants, data
access and assignment. The other sends were actually looked
up in some object. 11 were access to data slots or constants,
25 invoked a method, 9 executed a primitive operation while
10 executed the assignment primitive changing the value of
some data slot.
Status
All functionality is in place, but there is still debugging
to do. See the log file for details on
how the work is progressing. This is updated on every
change to the code, so be sure to check it periodically.
Bugs and Things To Do
- find bug in '|x| x: sortedSequence copyRemoveAll.
x add: 6. x add: 8. x add: 4. x' -
already returned block is scheduled for execution
- find bug that makes interleavedScheduler detect deadlock
when it should be a recursion (likely to be realted to
the previous one)
- program option for immutable objects to always be idle
- program option for closed blocks not to block
Release 2
This will be a new implementation, but like Release 1 it will
also run on top of Self 4.0. This tinySelf will be multiuser
from the start and won't use Self objects (it will allocate
tinySelf objects from one large byteVector).
Features
- Reflective Implementation
- Persistent Object Store
Status
Being Designed
Release 3
The x86 compiler (written in Self/tinySelf) will be used to
port Release 2 to Linux running on PCs. The second port will
make the system run directly on PC hardware. Future targets
for the compiler include a VLIW architecture, the PowerPC,
the ARM and the 68020.
Features
Status
Initial Studies
Release 4
The inclusion of the user interface on top of the previous release
will mark the transition from tinySelf to Merlin. After a few
months of beta testing, this Release will "go commercial".
Features
Status
General Architecture Being Designed
see also:
| new3 |
 | faq |
| faq |

 | tutorial |
| tiny |
| tutorial |
| tiny |

back to:


please send comments to jecel@lsi.usp.br
(Jecel Mattos de Assumpcao Jr).